下載投融界APP
隨時隨地獲取新鮮資訊
服務熱線:400-858-9000 咨詢/投訴熱線:18658148790
ChatGPT是革命性的數據模型,給我們帶來驚喜不僅僅是內容的生產方式的變化,更讓人們看到了通用人工智能的希望,推動AI大模型和新應用不斷涌現。隨著通用人工智能和人類真實的需求對齊,超大模型正在成為人工智能撬開廣大應用市場的利器。
大模型可以將復雜問題泛化成一個通用問題,極大縮短產業應用的周期。不過,另一個方面,大模型對于算力的要求將會更高,需要AI基礎設施的支撐。
當前針對大模型和基礎設施,國內外巨頭均已展開布局。收購OpenAI后,微軟對于其全力的支持,才成功研發出ChatGPT,讓微軟重回科技之巔。同時,微軟的智能云Azure是OpenAI的重要合作伙伴,為其提供了重要算力和云等基礎服務。
商湯早在2018年就開始大模型相關探索,當時叫做預訓練模型。2023年,商湯科技連續推出了多模態多任務通用大模型“書生(INTERN)2.5”和大模型體系“日日新SenseNova”。在商湯大模型的背后,是商湯科技新型AI基礎設施——商湯大裝置SenseCore。
2023年6月2日,臨港智能算力產業峰會中,臨港新片區智算產業聯盟正式成立,作為“新片區智算產業鏈鏈主”企業和聯盟的算力提供企業,商湯科技將與智算產業上下游及高校與科研院所共同開展資源共享、技術交流和項目合作。
可見,無論國外還是國內,眾多科技巨頭都已將大算力+大模型作為長期的戰略方向。
01
大模型時代,
算力到底有多重要?
2023年,國內外眾多科技巨頭紛紛布局大模型,比如谷歌發布了PaLM-E、阿里發布大模型“通義千問”、百度推出“文心一言”。
商湯科技4月發布“日日新SenseNova”大模型體系之后,在大裝置的賦能下實現了日新月異的飛速發展:開源了“書生2.5”多模態大模型,以及發布遙感大模型SenseEarth3.0、通才AI智能體GITM等等。近日,商湯科技、上海AI實驗室聯合香港中文大學、復旦大學及上海交通大學發布千億級參數大語言模型“書生·浦語”(InternLM)。“書生·浦語”具有1040億參數,是在包含1.6萬億token的多語種高質量數據集上訓練而成。
全面評測結果顯示,“書生·浦語”不僅在知識掌握、閱讀理解、數學推理、多語翻譯等多個測試任務上表現優秀,而且具備很強的綜合能力,因而在綜合性考試中表現突出,在多項中文考試中取得超越ChatGPT的成績,其中就包括中國高考各個科目的數據集(GaoKao)。
“書生·浦語”聯合團隊選取了20余項評測對其進行檢驗,其中包含全球最具影響力的四個綜合性考試評測集:
由伯克利加州大學等高校構建的多任務考試評測集MMLU;
微軟研究院推出的學科考試評測集AGIEval(含中國高考、司法考試及美國SAT、LSAT、GRE和GMAT等);
由上海交通大學、清華大學和愛丁堡大學合作構建的面向中文語言模型的綜合性考試評測集C-Eval;
以及由復旦大學研究團隊構建的高考題目評測集Gaokao;
實驗室聯合團隊對“書生·浦語”、GLM-130B、LLaMA-65B、ChatGPT和GPT-4進行了全面測試,針對上述四個評測集的成績對比如下(滿分100分)。
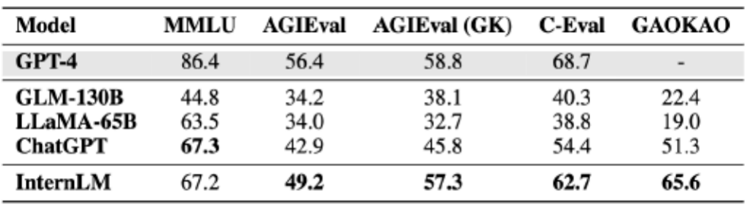
△評測成績
“書生·浦語”不僅顯著超越了GLM-130B和LLaMA-65B等學術開源模型,還在AGIEval、C-Eval,以及Gaokao等多個綜合性考試中領先于ChatGPT;在以美國考試為主的MMLU上實現和ChatGPT持平。這些綜合性考試的成績反映出“書生·浦語”扎實的知識掌握程度和優秀的綜合能力。
商湯科技聯合創始人、大裝置事業群總裁楊帆表示,在接下來2~3年之后,人工智能研究可能80%、90%都將轉向大模型。很多方向產業人工智能研發或將被大模型所替換,這也符合自然的技術研發進步延伸的過程,我們正奔向大模型時代。
大模型如火如荼,算力重要性同樣不言而喻。OpenAI作為微軟的子公司,背后對于算力或許不焦慮。可對于國內很多公司來說,背后或許并無微軟、谷歌、亞馬遜這樣的巨頭支撐,又該如何應對呢?
眾所周知,大模型需要在海量數據上進行訓練和優化,才能達到更高的預測準確性和泛化能力,隨著數據處理量增大,對于算力的需求也越高。比如,在ChatGPT的研發上,微軟就在Azure的六十多個數據中心部署了幾十萬張GPU,為OpenAI單獨使用。

△商湯科技人工智能計算中心
如今,中國科技巨頭已經開始肩負AI基礎設施建設的責任。比如,2021年,世界人工智能大會期間,商湯正式推出新型AI基礎設施——商湯大裝置SenseCore;2022年9月,商湯大裝置AI云也對外發布,并于2023年2月25日正式上線。商湯大裝置SenseCore在千卡集群上達到了90%的利用率,遠遠領先行業平均水準。
未來,是否擁有大模型與大算力是衡量一家人工智能企業能力的主要標準。也是打破國外“算力壟斷”,打造高效率、低成本、規模化的下一代AI基礎設施與服務的關鍵所在。
在算法層面,不管是商湯科技,又或者是其他AI科技公司,都在從小模型到大模型轉型。
在算力層面,經過5年探索,商湯科技人工智能計算中心(AIDC)去年在上海臨港正式投用,成為商湯大裝置SenseCore的重要算力基座,是亞洲目前最大的智能計算平臺之一,也是國內為數不多接近GPT所需算力的重要基礎設施。
臨港新片區黨工委副書記吳曉華在算力大會上表示,臨港新片區算力產業已在上游軟硬件、中游的數據中心、調度平臺,下游應用進行了相應布局。
上海臨港自貿區計劃到2025年,形成以智算算力為主、基礎算力和超算算力協同的多元算力供給體系,算力產業總體規模突破100億元;與此同時,總算力超過5EFLOPS(FP32),AI算力占比達到80%,建成公共算力服務平臺。商湯科技聯盟重要參與者,將會為臨港自貿區提供重要算力基礎服務。
未來,無論在政府和政策端,還是企業和應用端,算力都是AI技術發展的重要基礎設施。
李開復多次在公開活動中強調,不要忽視在基礎設施領域的投資,尤其是算力領域。能提高算力或者帶來新算法、新芯片等類型的企業,也是創新工場著重關注的領域。
IDC的數據,預計到2023年全球AI芯片市場規模將達到710億美元。
奇績創壇創始人兼CEO陸奇認為,大模型為先的新一代基礎設施是新時代早期的好“工具生意”。
AI的巨變前夕,率先掌握底層算力提供能力,或許可以在資本市場和應用市場雙線開花,實現名利雙收。
02
商湯大裝置的三大核心優勢
算力、數據、算法是AI傳統三要素,三者的結合造就了人工智能的廣泛應用。只不過,伴隨著通用人工智能時代(AGI)到來,數據量的攀升,市場對于算力和算法的要求越來越高。
未來,誰能為AI三要素提供更好地整合能力,以及更低成本、更低門檻的能力是決定其市場地位的關鍵。
在深潛atom看來,企業選擇人工智能基礎服務時,成本、性能和差異性都是重要參考目標,在選擇眾多之時,差異化服務或是決定企業選擇的關鍵。
提到人工智能基礎設施的差異化服務上,商湯科技也是繞不開的一家科技公司。其很早預見了AGI時代的到來,針對AI基礎設施展開了布局,并且推出商湯大裝置SenseCore——融合了算力、算法和數據處理能力,致力于打造高效率、低成本,規模化的新型人工智能基礎設施。

△商湯大裝置SenseCore
行業普遍認為算力就是基礎設施,但實際上人工智能基礎設施是算力、數據、算法(包括基礎算法和算法相關的工具)三位一體。算力不僅是硬件的資源,還包括上面一整套的基礎軟件體系;數據也不僅是數據本身的積累,還包括處理數據的能力、整合數據的能力、使用數據的know-how……誰能把這三者的整合能力提供得好,提供更低成本、更低門檻的能力是決定整個競爭的關鍵,也是商湯大裝置想去做的。
在AI基礎設施的擴建中,有效算力的提升是個挑戰。有時候并行500P算力的GPU,實際上有效算力可能只有200P或者300P,GPU的利用效率并不高。因此,如何實現高性能計算優化,以及異構網絡的調試是核心關鍵。
當前,商湯科技大模型并行訓練服務支持單集群3200卡5000億稠密參數模型訓練,在千卡集群上達到了90%的利用率,遠遠領先行業平均水準。
商湯大裝置SenseCore已經完成2.7萬塊GPU的部署并實現了5.0exaFLOPS的算力輸出能力。目前,商湯大裝置SenseCore可最多支持20個千億參數量大模型(以千卡并行)同時訓練,最高可支持萬億參數超大模型的訓練。
更為關鍵的是,商湯大裝置SenseCore有三大差異性優勢。
首先,商湯科技是AI原生,熟悉各個環節。從芯片、服務器、基礎軟件、工具軟件、算法生產到應用,商湯科技都有布局和成就,沉淀了大量的專家認知和工具,對每個環節的困難、挑戰都有足夠的經驗。因此,在硬件服務器的配置,訓練類型的配置,推理類型的配置,訓練和推理之間的關系分析,以及集群內部的網絡調度等領域,都可以更好地為用戶提供關鍵性建議。
其次,商湯有成熟的端到端應用解決方案。商湯科技很早就針對“一平臺四支柱”(AI大裝置+智能汽車、智慧生活、智慧商業、智慧城市)進行前瞻性戰略布局,并擁有豐富的AI產業應用經驗,更了解不同行業對于AI的需求,從而可以更好地提供端到端綜合服務。
比如,商湯科技已經構建的業界首個感知決策一體化的端到端自動駕駛解決方案UniAD,在多項關鍵數據集與指標上超越了SOTA方法。使得車道線的預測準確率提升了30%,預測運動位移的誤差降低了近40%,規劃誤差降低了近30%。
△商湯大模型賦能絕影“駕艙云”三位一體
馬化騰表示,要把底層的算法、算力和數據扎扎實實做好十分關鍵,更關鍵的是場景落地。對于用戶來說,可選擇性或許很多,真正要做產業落地的時候,AI是要拿端到端價值說話的。
在開源生態的建設上,商湯也有獨特的優勢。在人工智能時代,最重要的不是框架,真正的核心價值全都沉淀在算法和模型里。基于商湯長期的開源生態積累,商湯大裝置的算法模型層,提供OpenMMLab、OpenGVLab、OpenDILab三套開箱即用的開源算法體系。其中人工智能算法開源體系OpenMMLab在GitHub上已獲得超7.5萬多個星標,用戶遍及超過110個國家和地區,是深度學習時代極受歡迎的計算機視覺開源算法平臺之一。
商湯科技還被授予“新片區智算產業鏈鏈主”企業,將基于商湯人工智能計算中心(AIDC)積極參與臨港智算產業鏈的協同融合和集聚發展。
03
大裝置+大模型
“引爆”大規模場景應用
通用大語言模型成熟之前,我們和算法的交流需要通過一些標準句式,體驗感并不好。現如今,伴隨著通用大語言模型成熟,我們可以采取和正常人溝通的方式和算法溝通,并且得到正確的回應。大模型帶來的不光是效率的提升,更讓原來一些體驗不夠好形成大規模應用的場景,到今天可以形成大規模應用。
臨港算力大會上,上海市經濟信息化委副主任湯文侃表示,希望臨港新片區探索將“網絡、數據、算力、安全”聯動創新的合作模式,利用AI算法將行業數據轉化為產業知識,從而賦能千行百業。
落地永遠是對研發的最重要檢驗標準。作為臨港新片區智算產業聯盟重要成員,商湯科技正在用實際行動回應算力在落地中的重要價值。
截至今年5月,商湯大裝置已累計服務超40個核心客戶,其中大模型客戶10家以上,涵蓋智能駕駛、生物制藥、芯片設計、智慧商業、高校科研等前沿領域,并已在超過20個落地場景中實現大模型交付。
例如,2023年5月,商湯科技在CHIMA2023公布了全新升級“SenseCare?智慧醫院”綜合解決方案,在“大模型+大算力”的驅動下,SenseCare?智慧診療平臺已經搭載20余款AI輔助診斷應用。
商湯科技董事長、CEO徐立表示,通用人工智能時代,模型的能力可以用算力來衡量。商湯大裝置SenseCore已經打造通用人工智能時代的基礎設施,在模型的迭代速度及處理問題的能力上日日更新。商湯科技十分期待與更多同行者建立縱深合作,共商行業新模式,共探未來新方向。
毫無疑問,AI產業即將迎來一個更加繁榮的大航海時代。以商湯科技為代表的企業,正在為人工智能提供強大的計算和存儲能力,讓AI技術更加低成本、低門檻、高效率地進入到各個場景里面,推動未來產業生態的百花齊放。